Postgres provides many index types such as B-tree, hash, GiST, and GIN. This article is about commons indexes like B-Tree and Hash to tell what is difference and which one should use for the situation. GiST and GIN are indexes for supporting Full-Text Search which I’ll explain in the new blog post.
Hash index
Hash index is probably the fastest and the simplest index with O(1) the data will store in hashmap structure. for example when you query and the key index hit the hash map will return address to data storage is instantly. Hash index in Postgres doesn’t support composite or multi-columns index and Hash index don’t have ability for ordering or select between range, Unlike B-tree index it can do the job.
Examples
Prepare schema and Create an Hash indexes for first_name and last_name.
>CREATE TABLE persons (
id int PRIMARY KEY,
first_name text,
last_name text
);
CREATE INDEX first_name_idx ON persons USING hash (first_name);
CREATE INDEX last_name_idx ON persons USING hash (last_name);
INSERT INTO persons VALUES (1, 'john', 'doe');
INSERT INTO persons VALUES (2, 'jane', 'doe');
INSERT INTO persons VALUES (3, 'jack', 'doe');
INSERT INTO persons VALUES (4, 'john', 'connor');
persons table
| id (PK) | first_name | last_name |
|---|---|---|
| 1 | john | doe |
| 2 | jane | doe |
| 3 | jack | doe |
| 4 | john | connor |
Example 1. When query by column
>EXPLAIN SELECT * FROM persons WHERE last_name='doe';
The query will hit last_name_idx index and the index will return all addresses to all rows which last_name is ‘doe’ instantly.
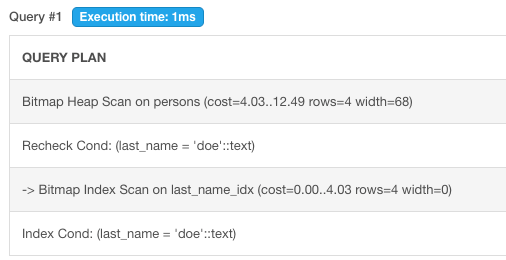
Example 2. When query by multi columns
>EXPLAIN SELECT * FROM persons WHERE first_name='john' AND last_name='doe';
The query will using first_name_idx index and last_name_idx index. I have no idea why it checks last_name_idx first. I tried to swap where condition but the plan still the same.

B-Tree index
B-tree index will store data in tree structure that allow for sorted, search, and sequence data in O(log n). B-tree structure is not like normal binary search tree, a node can have more than one key and more than two children. That’s why B-tree is suit for database because allow more complexity in search condition.
Examples
Prepare schema and Create an B-Tree indexes for salary and multi columns index with age and salary.
>CREATE TABLE employees (
id int PRIMARY KEY,
name text,
salary int,
age int
);
CREATE INDEX salary_idx ON employees USING btree (salary);
CREATE INDEX age_salary_idx ON employees USING btree (age, salary);
INSERT INTO employees VALUES (1, 'john', 3000, 25);
INSERT INTO employees VALUES (2, 'jane', 1000, 30);
INSERT INTO employees VALUES (3, 'jack', 2000, 40);
INSERT INTO employees VALUES (4, 'jill', 5000, 50);
employees table
| id (PK) | name | salary | age |
|---|---|---|---|
| 1 | john | 3000 | 25 |
| 2 | jane | 1000 | 25 |
| 3 | jack | 2000 | 40 |
| 3 | jill | 5000 | 25 |
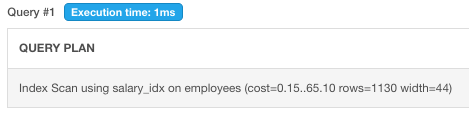
Example 1. When query all ordering by index
>EXPLAIN SELECT * FROM employees ORDER BY salary;
the query will using index salary_idx to order all employees.
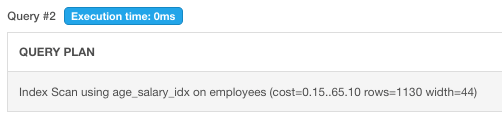
Example 2. When query all ordering by composite index
>EXPLAIN SELECT * FROM employees ORDER BY age;
the query will use index age_salary_idx to order all employees. This proves that the multi-columns index can also order by one field.
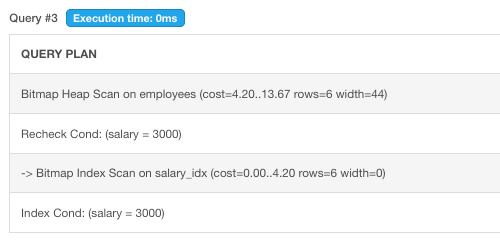
Example 3. When query by a column using index
>EXPLAIN SELECT * FROM employees WHERE salary = 3000;
As the query plan after the index hit still needs to bitmap Heap scan after and it took 4.20..13.67 cost which means startup cost is 4.2 and the total cost is 13.67. that is why the b-tree index is not O(1).
Example 4. When query by multiple column using composite index
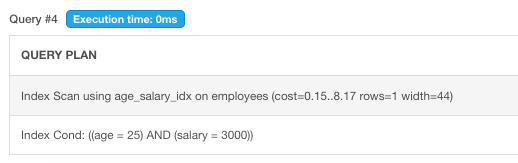
>EXPLAIN SELECT * FROM employees WHERE age = 25 AND salary = 3000;
This is a bit surprising. when query exactly multi-columns to the composite index after it hit the index it will return the result instantly. This is probably O(1) in this situation.
Conclusion
The key point is to create an index base on the queries you are using. B-tree for ordering query and hash for non-ordering. You can create many indexes as you want to improve the read performance. The disk space or the block size might not a big deal nowadays. Once a query doesn’t hit any index and it’s often used, you should consider how to indexing it.
Reference
https://www.postgresql.org/docs/current/indexes-types.html
http://itdoc.hitachi.co.jp/manuals/3020/3020635200e/W3520279.HTM
https://user3141592.medium.com/single-vs-composite-indexes-in-relational-databases-58d0eb045cbe